大厂(转转、携程、京东)都用分代ZGC,卡顿降低20倍,吞吐量提升4倍
案例1: 携程的要全面升级jdk21 的消息:
网上有小道一个消息说携程要全面升级jdk8到jdk21了,jdk8其实是2014年正式发布的,正式发布已经有10年的时间了。
这次升级应该跟spring boot也有关,大家都知道从spring boot 3.0开始,最低支持的Java版本已经是17了,由于spring boot基本已经是所有Java后端应用的必备框架了,所以很多公司开始不得不开始慢慢升级jdk版本了。
案例2: 转转升级jdk21的压测数据
- 平均使用率:上涨20%
- 最大内存使用率:基本不变,使用率为98%
- GC暂停时间:几乎无暂停,分代ZGC单次停顿时间不超过1ms,暂停QPS为2~3
- GC Allocation Stall次数:降低85%(638-->94次)
- QPS:提升15%(737-->842)
- TPAvg:降 500 ms(1300-->788ms)
- TP90:降低 300 ms(1963-->1660ms)
- TP99:降低 2.5 s(4473-->1967ms)
- 错误比率降低了28个百分点(40.88%-->12.91%)
综上,分代ZGC可提高资源利用率,更低的Allocation Stall次数,更高的集群QPS,更低的TP,更低的接口错误率,垃圾回收几乎没有停顿。
至此,可全量使用JDK21分代ZGC。
转转实践表明,ZGC 在低延迟、高吞吐、大堆场景下全面优于 G1,尤其适合电商、实时交易等对稳定性要求高的业务。
案例3:某厂 JDK21 技术选型说明
以下案例来自互联网 某厂:
前几个月搞新项目,做技术选型时,评估了一下,决定使用JDK21, 主要的评估点:
- JDK21已经出了LTS长期支持版本,而且按Oracle官方说明,是免费使用的:https://www.oracle.com/hk/java/technologies/downloads/#java21 JDK 21 binaries are free to use in production and free to redistribute, at no cost, under the Oracle No-Fee Terms and Conditions (NFTC).
- 从JDK8到JDK21,引入了很多的性能优化,包括GC改进,之前看到过一个性能评测,同样的代码,在JDK21也比JDK8下运行要快10%~30%,不过现在找不到那个链接了,不过google搜索一下还是有很多类似的性能评测文章的;
- SpringBoot的3.最新版本,已经不支持JDK8了,例如现在的Stable稳定版3.3.5,要求JDK17:https://docs.spring.io/spring-boot/system-requirements.html 而SpringBoot2.的商业支持只到2025年2月:https://spring.io/blog/2022/05/24/preparing-for-spring-boot-3-0
- JDK21 拥有 更加轻量级的 的虚拟线程,也就是协程
- 新项目,没有任何历史债务,又是探索型项目,工期要求不那么急,那就让团队进步一下,搞吧。
最终决定选型:JDK21 + SpringBoot3.3.1
实际上,除了 oralce JDK21 NFTC 版本,还有有很多公司都推出了发行版,基本上都可以下载和使用,这里列举几个:
- oralce推出的NFTC版本:https://www.oracle.com/hk/java/technologies/downloads/#java21 NFTC是指:Oracle No-Fee Terms and Conditions许可
- 微软LTS发行版:https://learn.microsoft.com/zh-cn/java/openjdk/download-major-urls#openjdk-21-lts
- Eclipse发行版:https://adoptium.net/zh-CN/temurin/releases/
- OpenLogic发行版:https://www.openlogic.com/openjdk-downloads
生产环境,建议用的当然还是Oracle的版本了。
JAVA 30年的发展历程, JDK 21分代的必要性
在JAVA 30年的发展历程中,JVM提供了多种多样的垃圾回收器:
- 串行垃圾回收器(Serial Collector):一种简单的垃圾回收器,它会暂停所有应用程序线程,适用于客户端类型的机器,但不适用于多线程服务器环境。
- 并行垃圾回收器(Parallel Garbage Collector):在JDK5到JDK8中被使用,它是多线程环境下的一个不错选择。它使用多个线程来管理堆空间,但在执行垃圾回收时也会冻结其他应用程序。
- CMS(Concurrent Mark Sweep):核心设计上较之前垃圾回收器更为复杂。它更倾向于较短的垃圾回收暂停时间,并且在应用程序运行时能够与垃圾回收器共享处理器资源。CMS的平均响应速度较慢,但不会暂停应用程序线程来执行垃圾回收操作。
- G1(Garbage First Collector):CMS的替代产品,为拥有大内存空间的多处理器机器设计的,它将堆划分为多个Region,解决了CMS内存碎片化和回收暂停时间无法预先配置的问题。
- ZGC(Z Garbage Collector):ZGC是一种并发的、分页的、支持NUMA的垃圾回收器,它使用coloured指针、load barriers 。其中coloured指针是 ZGC 的核心概念,ZGC使用指针中的某些高位来标记对象所处的GC阶段。ZGC能处理大小从 8MB 到 16TB 的堆内存范围。
JDK 21之前的ZGC是不支持分代的。
不分代时,ZGC将所有对象存储在一起,无论年龄大小,ZGC必须在每次运行时扫描所有对象。
当服务器压力较大时,不分代,极有可能导致内存回收速率跟不上应用申请内存速率,进而触发Allocation Stall (分配暂停)。
Allocation Stall (分配暂停) 不是全堆暂停,而是线程粒度的分配暂停,直到 应用线程可以重新申请新内存,方可继续执行,Allocation Stall (分配暂停) 极大的影响服务可用性。
Allocation Stall:内存回收速率跟不上应用申请内存速率时触发(即:内存不足时),会引发应用线程停顿,类似Stop The World,应最大限度避免。
于是,JDK 21引入了分代ZGC Generational ZGC ( JEP 439) ,试图减少 Allocation Stall (分配暂停) , 事实上也确实做到了,在转转团队的 对比压测中,GC Allocation Stall次数:降低85%(638-->94次),具体请参考后面的指标数据。
首先,从理论上来说,内存 分代的必要性
分代回收主要是基于两个假说:
- 弱分代假说(Weak Generational Hypothesis):绝大多数对象是朝生暮死,在年轻时死亡。
- 强分代假说(Strong Generational Hypothesis):熬过多次垃圾回收的老年对象往往难以死亡。
因此,收集年轻对象消耗的资源较少,回收的内存较多;而收集老年对象消耗的资源较多,回收的内存较少。
所以,转转可以通过更频繁地收集新生代对象来提高使用ZGC的资源利用和性能。
基于「大部分对象朝生夕死」的弱分代假说,ZGC 显然可以更进一步优化当前的实现。
「大部分对象朝生夕死」 的场景下, 对于那些生命期短的对象要经常回收,获取高收益,对于那些生命期长的对象尽量不要浪费时间去回收。
所以基于分代 ZGC 不仅能达到亚毫秒级延迟,甚至在很多情况下会比非分代 ZGC 使用更少的内存,且有更少的吞吐量损失。
ZGC 分代的必要性
在程序运行过程中很多对象生命期较短,对这些短生命期对象进行回收,可以回收很多内存空间;
剩余那部分生命期较长的对象,一般也不会被回收掉,所以对这些长生命期对象进行回收,可以回收的内存就比较有限了。
所以,不应该对所有对象都一视同仁。
对于那些生命期短的对象要经常回收,获取高收益,对于那些生命期长的对象尽量不要浪费时间去回收。

ZGC分代 的演进 ,以及和 不分代 ZGC 大概对比
在JDK的发展中,ZGC(Z Garbage Collector)从最初的不分代设计逐步演变为分代模式,这是其核心机制的重要优化。
1 初始阶段(JDK 11-20)
ZGC最早于JDK 11作为实验性功能推出,此时采用不分代设计,通过并发压缩、染色指针等技术实现低延迟(STW停顿不超过10ms) 。
核心目标是通过并发操作减少暂停时间,但由于没有进行分代设计, 存在内存回收效率不足的问题,需频繁扫描整个堆 。
2 分代模式引入(JDK 21-23)
JDK 21首次引入分代ZGC,将堆划分为年轻代(Young Generation)和老年代(Old Generation),针对性优化回收策略 。
JDK 23将分代ZGC设为默认模式(JEP 474),标志着其稳定性和生产适用性成熟。
- 年轻代:存放短生命周期对象,采用高频回收策略(Minor GC),避免存活对象快速进入老年代68。
- 老年代:存放长生命周期对象,通过低频并发标记-压缩(Major GC)减少扫描开销16。
分代 ZGC 与不分代 ZGC 的性能对比分析
从 JDK 21 开始引入的分代 ZGC 相比传统的不分代 ZGC,在性能优化方面实现了以下提升:
1:吞吐量提升
在相同堆内存条件下,分代 ZGC 的吞吐量可达到不分代 ZGC 的 4 倍 。
这一改进主要得益于分代机制:通过更频繁地回收年轻代对象(基于弱分代假说),减少了对老年代对象的扫描频率,从而提高了垃圾回收效率 。
2:内存利用率优化
分代 ZGC 的内存开销显著降低,相同场景下所需堆内存仅为不分代 ZGC 的 70% 。
分代机制允许堆划分为年轻代和老年代,年轻代区域更小且回收频率更高,降低了内存碎片化风险 。
3:延迟控制
分代 ZGC 仍保持了不分代 ZGC 的亚毫秒级停顿时间(小于1ms),但通过分代策略减少了 Allocation Stall(分配停顿)的发生频率 85%左右。
并发处理机制结合染色指针技术,确保垃圾回收与应用程序线程的并行执行,进一步优化延迟 。
4:适用场景扩展
分代 ZGC 在 大内存堆(TB 级)场景下表现更稳定,尤其适合对延迟敏感的高并发应用(如实时交易系统、高频查询服务)。
对比不分代 ZGC,分代版本在混合负载(如同时存在短期存活对象和长期存活对象)场景下性能优势更显著。
分代 ZGC 与不分代 ZGC 的 大致对比

分代 ZGC 未来将成为默认选项,最终取代不分代 ZGC
大回顾: JDK 21之前 不 分代的ZGC 的全面回顾
ZGC 是一款在 JDK 里,针对垃圾回收推出的并发垃圾收集器。
在 Java 程序运行时,它能同步完成垃圾收集的主要工作,极大降低垃圾回收对应用程序响应时间的影响。
首先,回顾一下 JDK 21之前的不 分代的ZGC 。
下面 将从设计特点、对象地址、内存管理、读屏障、工作流程几个方面,回顾一下 JDK 21之前的不分代的ZGC 。
一、不分代 ZGC 设计特点
(1)分页管理支持大内存
为支持 TB 级别的 超大堆内存,ZGC 采用基于页面(page)的分页管理,类似于 G1 收集器的分区 Region 机制,借此实现对海量内存的有效管理。
(2)指针染色优化标记移动
为快速完成对象的并发标记与并发移动,ZGC 对内存空间重新划分,引入指针染色技术。
通过对指针的特定操作,在指针中记录对象的状态信息,提高垃圾收集效率。
(3)两级内存管理
为实现更高效的内存管理,ZGC 设计了物理内存和虚拟内存两级管理机制,优化内存的分配与回收。
(4)NUMA - Aware 架构下 本地内存 无锁分配
在 NUMA(非统一内存访问架构)架构下,每个处理器核心拥有独立管理的本地内存,访问其他核心的内存时速度较慢。
ZGC 通过优先在请求线程所在处理器的本地内存上分配对象,优化内存访问效率,减少因内存访问带来的性能损耗。
(5)运行环境与限制
ZGC 仅支持 Linux 64 位系统,不支持 32 位平台,因此也无法使用压缩指针。
二:不分代 ZGC的内存布局
ZGC和G1一样也采用了分区域的堆内存布局,不同的是,ZGC的Region(官方称为Page,概念同G1的Region)可以动态创建和销毁,容量也可以动态调整。
ZGC的Region分为三种:
- 小型Region容量固定为2MB,用于存放小于256KB的对象。
- 中型Region容量固定为32MB,用于存放大于等于256KB但不足4MB的对象。
- 大型Region容量为2MB的整数倍,存放4MB及以上大小的对象,而且每个大型Region中只存放一个大对象。由于大对象移动代价过大,所以该对象不会被重分配。

重分配集(Relocation Set)/ 重定位集
G1中的回收集用来存放所有需要G1扫描的Region,而ZGC为了省去卡表的维护,标记过程会扫描所有Region,如果判定某个Region中的存活对象需要被重分配,那么就将该Region放入重分配集中。
通俗的说,如果将GC分为标记和回收两个主要阶段,那么回收集是用来判定标记哪些Region,重分配集用来判定回收哪些Region。
三、不分代 ZGC 的染色指针地址(颜色地址)
不同的 HotSpot 虚拟机收集器,标记实现方案有所不同。Serial 收集器将标记直接记录在对象头上,G1 和 Shenandoah 使用 BitMap 结构记录标记信息,而 ZGC 则把标记信息直接记录在引用对象的指针上。
(一)传统对象 的 GC 信息
在 ZGC 出现之前,GC 信息保存在对象头的 Mark Word 中。
以 64 位 JVM 为例,其使用 64 位地址空间,但对象大小并非固定为 64 字节。
对象在内存中的布局如下:
(1)对象头
- Mark Word:存储对象的哈希码(首次计算时会缓存)、GC 状态(用于标记对象是否可达)、锁信息(轻量级锁、重量级锁、偏向锁等)。
- Klass Pointer(类指针):指向对象的类元数据,即 Class 对象的内存地址,JVM 通过它获取对象的类型信息,包括类的字段、方法、接口等。
(2)实例数据 :
存储对象的实际数据,即类中定义的实例变量,按字段顺序排列。
例如,对于包含int和String类型字段的Person类,实例数据部分会依次存储这两个字段的值。
(3)对齐填充 :
为确保对象在内存中按特定规则对齐,JVM 会进行填充。
如 32 位机器上,对象大小通常需为 8 的倍数,若实际数据不满足,会插入填充字节。
(二)不分代 ZGC 地址的 GC 信息
ZGC 则把标记信息直接记录在引用对象的地址上, 没有放在 对象头的 Mark Word 了。
ZGC 引用对象的地址 添加了 四个标志位,JVM 可直接获取对象的三色标记状态(Marked0、Marked1)、是否进入重分配集(Remapped)、是否需要通过 finalize 方法访问(Finalizable)等信息, 标识 对象的 GC状态。
ZGC 通过 地址 标识 GC状态,而 无需访问对象本身,大幅提高 GC 效率。

ZGC 引用对象的地址 的三个 染色位:
- Remapped:对象被重新映射到新内存位置,即对象移动过。
- M1:上次 GC 标识过。
- M0:本次 GC 标识过。
ZGC 地址限制:受 X86_64 处理器硬件限制,其地址线只有 48 条,除去 4 位染色指针,剩余 44 位可用对象地址,理论上支持 16TB 内存。
但目前 ZGC 宣称最大支持 4TB 内存,这是人为限制,目的是平衡性能、稳定性和实际需求。因为 42 位地址的最大寻址空间为 4TB。
四、不分代 ZGC 虚拟内存映射技术
染色指针只是JVM定义的,操作系统、处理器未必支持。
为了解决这个问题,ZGC在Linux/x86-64平台上采用了虚拟内存映射技术。
ZGC为每个对象都创建了三个虚拟内存地址,分别对应Remapped、Marked 0和Marked 1,通过指针指向不同的虚拟内存地址来表示不同的染色标记。

ZGC 仅支持 64 位系统,将 64 位虚拟地址空间划分为多个子空间。
创建对象时,先在堆空间申请虚拟地址,该地址暂时不映射到物理地址。
同时,ZGC 会在 M0、M1、Remapped 空间中为对象分别申请虚拟地址,这三个虚拟地址映射到同一物理地址。
ZGC 通过切换这三个视图空间,实现并发垃圾回收。
五、不分代 ZGC 读屏障 和 指针的地址“自愈”
ZGC 通过 读屏障来完成指针的“自愈”,由于ZGC目前没有分代,且ZGC通过扫描所有Region来省去卡表使用,所以ZGC并没有写屏障,这成为ZGC一大性能优势。
当程序读取对象时,读屏障会执行以下操作:
- 检查指针染色:
读屏障首先检查指向对象的指针的颜色信息,获取对象状态。 - 处理移动的对象:
若指针表明对象已在垃圾回收过程中被移动,读屏障会确保返回对象的新位置。 - 确保一致性:
通过上述操作,ZGC 在并发移动对象时,维持内存访问的一致性,减少应用程序停顿。
读屏障可被 GC 线程和业务线程触发,仅在访问堆内对象时生效,访问 GC Roots 时不会触发,这也是扫描 GC Roots 时需要停顿所有线程(STW)的原因。
六:无锁架构:NUMA - Aware 架构下 本地内存 无锁分配
多核CPU同时操作内存就会发生争抢,现代CPU把内存控制系统器 集成到处理器内核中,每个CPU核心都有属于自己的本地内存。
在NUMA架构下,ZGC会有现在自己的本地内存上分配对象,避免了内存使用的竞争。
在ZGC之前,只有Parallet Scavenge支持NUMA内存分配。

七、不分代 ZGC 工作流程
ZGC,几乎所有运行阶段都和用户线程并发进行。
ZGC 的步骤大致可分为三大阶段分别是标记、转移、重定位。

- 标记:从根开始标记所有存活对象
- 转移:选择部分活跃对象,转移到新的内存空间上
- 重定位:因为对象地址变了,所以之前指向老对象的指针都要换到新对象地址上。
ZGC 将内存划分为固定大小的页面,通常为 2MB,用于存储对象和管理内存。
(1)初始标记
ZGC 标记所有从 GC Root 直接可达的对象。
(2)并发标记 & 重新映射
并发标记阶段和G1相同,都是遍历对象图进行可达性分析,不同的是ZGC的标记在染色指针上。
1、 初次 GC:从 GC Root 开始,对堆中对象进行可达性分析。
2、二次 GC:修正上次 GC “并发迁移” 阶段迁移对象的指针,使其指向新分区。
(3)再标记
标记上一次标记过程中新产生的对象。
(4)并发转移准备
为对象转移做前置准备,包括引用处理、弱引用清理和重分配集选择等。
在这个阶段,ZGC会扫描所有Region,如果哪些Region里面的存活对象需要被分配的新的Region中,就将这些Region放入重分配集中。
此外,JDK12后ZGC的类卸载和弱引用的处理也在这个阶段。
(5)初始转移
将根节点直接引用的对象迁移到新分区,此阶段需停顿所有应用线程(STW),但因仅迁移根节点直接引用的对象,停顿时间较短。
(6)并发转移
并发迁移 “并发标记” 阶段标记的对象到新分区,此时对象引用指针尚未修改,仍指向原位置。
ZGC在这个阶段会将重分配集里面的Region中的存货对象复制到一个新的Region中,并为重分配集中每一个Region维护一个转发表,记录旧对象到新对象的映射关系。
如果在这个阶段用户线程并发访问了重分配过程中的对象,并通过指针上的标记发现对象处于重分配集中,就会被读屏障截获,通过转发表的内容转发该访问,并修改该引用的值。
ZGC将这种行为称为自愈(Self-Healing),ZGC的这种设计导致只有在访问到该指针时才会触发一次转发,比Shenandoah的转发指针每次都要转发要好得多。
另一个好处是,如果一个Region中所有对象都复制完毕了,该Region就可以被回收了,只要保留转发表即可。
(7)并发重映射 / 下一轮 GC的 阶段2
最后一个阶段的任务就是修正所有的指针并释放转发表。
这个阶段的迫切性不高,所以ZGC将并发重映射合并到在下一次垃圾回收循环中的并发标记阶段中,反正他们都需要遍历所有对象。
(8) 总结
现代的垃圾回收器为了低停顿的目标可谓将“并发”二字玩到极致,
ZGC直接采用了染色指针、NUMA等黑科技,目的都是为了让Java开发者可以更多的将精力放在如何使用对象让程序更好的运行,剩下的一切交给GC,转转所做的只需享受现代化GC技术带来的良好体验。
基础原理: JDK 21分代ZGC的基础原理
JDK21的分代ZGC简介
ZGC是一个可伸缩的低延迟垃圾收集器,最高能支持TB级堆内存,能并发执行繁重任务,且不会让应用的暂停时间超过1ms。
ZGC适用于要求低延迟的应用,暂停时间与所使用的堆大小无关。
分代ZGC是ZGC的一个实现版本,依据假说:应用中的大部分对象都是短生命周期的,被设计为分代,即:年轻代、老年代。
相对ZGC,分代ZGC提高了应用吞吐率、降低了Allocation Stall频率、且依然能够保持对应用的暂停时间小于1ms。
- JDK21之前:
ZGC 的堆内存也是基于 Region 来分布,不过 ZGC 不区分新生代老年代的。 - JDK21之后:
分代ZGC为 年轻和年老的对象保留不同的世代, 这将使 ZGC 能够更频繁地收集年轻对象,因为年轻对象往往在很年轻时就会死亡。
分代ZGC内存模型
分代ZGC将堆内存分为两个逻辑区域:年轻代、老年代

当分配对象时,它首先会被分配到年轻代,如图所示。

若该对象经历过多次年轻代回收后依然存活,它将会被晋升到老年代

在实际的内存分布中,年轻代、老年代会分布在不连续的内存区域

分代 ZGC 标记与回收流程分析
回收一个代的阶段如图所示,包含:垂直方向的GC暂停,以及水平方向的并发阶段。
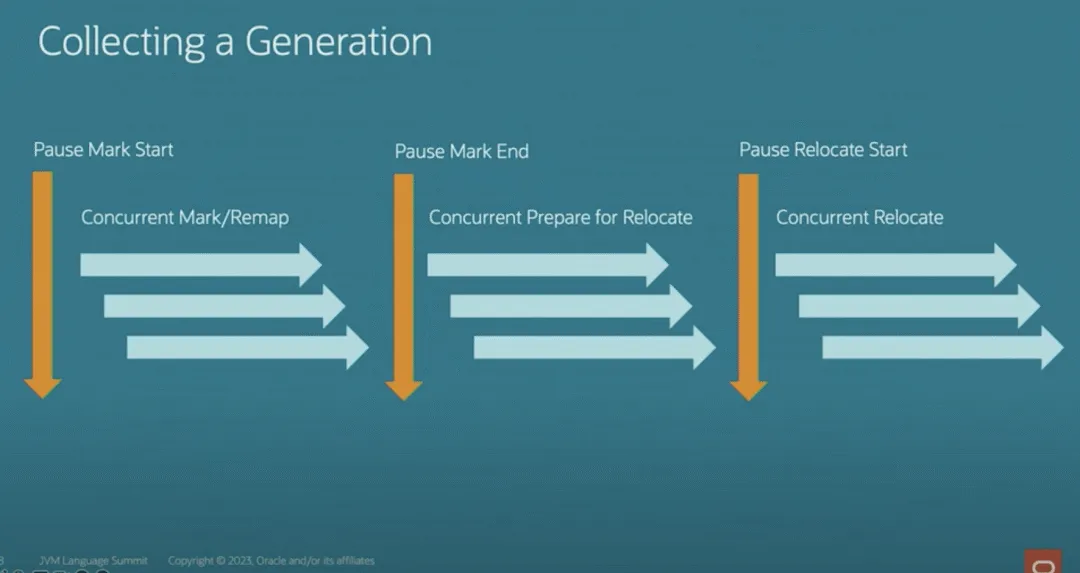
上图中, 可以看到 3次暂停点 和3次并发阶段。
- (1)暂停点1:这是一个同步点,仅标识标记开始。
- (2)并发阶段1:开始运行应用程序、并发标记获取对象是否可达,在并发标记的同时,对最近一次GC Cycle内的对象remapping(当我们获取对象引用时,分代ZGC的load barrier会检查对象引用,若对象引用过期,会生成新的对象引用,这个过程称为remapping)。
- (3)暂停点2:这是也一个同步点,用于标识标记结束。
- (4)并发阶段2:为疏散区域(Region)做准备工作、处理reference、类的卸载等。
- (5)暂停点3:同样也一个同步点,用于标识将要移动对象。
- (6)并发阶段3:移动对象,以便释放出连续的内存。
在分代ZGC各阶段(Phases)中,年轻代回收阶段、老年代回收阶段以及应用程序的运行完全是并发的,如图所示。
所以说, 分代ZGC的GC阶段与ZGC的GC阶段类似,也分为3次STW和3次并发阶段。
- 1 初始标记(STW):
标识标记开始,该阶段从GC roots和老年代remembered set出发找到根集合直接引用的活跃对象,并将其入栈 - 2 并发标记 :
此阶段主要做两个工作- 2.1 并发标记:
将初始标记找到的对象作为根,深度遍历对象的成员变量进行标记。此阶段需要考虑引用关系变化导致的漏标记问题 - 2.2 引用重定向:
对最近一次GC Cycle内的对象remapping(当转转获取对象引用时,分代ZGC的load barrier会检查对象引用,若对象引用过期,会生成新的对象引用,这个过程称为remapping)
- 2.1 并发标记:
- 3 再标记(STW):
在标记任务结束后尝试终止标记动作,由于GC线程和应用线程并发执行,有可能在GC工作线程结束标记后,应用线程又有了新的引用关系,因此需要STW判断是否真的结束了对象标记,如果没有结束,则需要并行标记。 - 4 并发准备转移:
并发选择待回收的页面,并发初始化待转移的页面,初始化Forwardding Table - 5 初始转移(STW):
转移根对象直接引用的对象 - 6 并发阶段:
并发转移,将对象移动到新页面。
分代ZGC将回收阶段:年轻代回收和老年代回收
在分代ZGC各阶段(Phases)中,年轻代回收阶段、老年代回收阶段以及应用程序的运行完全是并发的

分代ZGC将回收阶段划大致分为两类:Minor Collections和Major Collections, 以统一管理。
1、Minor Collection 年轻代回收:
该阶段只回收年轻代,访问年轻代以及老年代对象中指向年轻代对象的字段,访问他们的主要原因是:
(1)GC Marking Roots:这样的字段包含唯一引用,使年轻代Object Graph的一部分保持可达。GC必须将这些字段视为Object Graph的根,以确保所有存活的对象都被发现,并标记他们的存活状态。
(2)老年代中的陈旧指针:收集年轻代时,会移动对象,这些对象的指针没有被立即更新。
老年代到年轻代的指针集合称为remembered set,包含了所有指向年轻代的指针。

2 、Major Collection 全堆回收:
该阶段期望回收整个堆,既访问年轻代,也访问老年代。
和Minor Collection类似,找到GC Marking Roots,以及年轻代中指向老年代的Roots。
当年轻代收集完之后,可以找到所有老年代中存活的对象。当估算到所有存活的对象之后,就可以移动对象、回收内存。

分代ZGC的核心机制
分代ZGC将堆划分为两个逻辑区域:年轻代、老年代,二者的回收完全独立。 分代ZGC关注更有回收价值的年轻代对象。
与ZGC一样,分代ZGC的执行和应用运行并发。
由于与应用程序同时需要读取/修改Object Graph,必须为应用程序提供一致的Object Graph 对象视图。
分代ZGC通过:colored pointers(染色指针)、load barrier(加载屏障)、store barrier(存储屏障)实现,不再使用multi-mapped memory做多次映射。
分代ZGC不再使用多重映射
染色指针,是指向堆中对象的指针,和对象内存地址一起包含了对对象已知状态进行编码的元数据,元数据描述了:地址是否正确、对象是否存活等。
不分代 ZGC 采用一种称为彩色指针的技术。为了避免掩码指针的开销,不分代 ZGC 采用了多重映射技术。
多重映射是指将多段虚拟内存映射到同一段物理内存。
ZGC使用Java堆的3个视图(“marked0”,“marked1”,“remapped”),即3种不同“颜色”的堆指针和同一个堆的3个虚拟内存映射。
因此,操作系统可能会报告 3 倍大的内存使用量。
例如,对于 512 MB 的堆,报告的已提交内存可能高达 1.5 GB,不包括堆以外的内存。
注意:多重映射会影响报告的使用内存,但物理上堆仍将使用 512 MB 的 RAM。这有时会导致一个有趣的效果,即进程的 RSS 看起来大于物理 RAM 的数量。
在上述描述中,RSS(Resident Set Size)统计指的是进程实际驻留在物理内存中的内存大小统计。
在操作系统中,进程可能会使用虚拟内存,虚拟内存中的一部分数据会被加载到物理内存中供进程实际使用,这部分实际占用物理内存的大小就是 RSS。
对于 ZGC 来说,之前使用 multi - mapped memory(多映射内存)可能会导致 RSS 统计值异常,比如统计值达到 ZGC 实际内存使用的 3 倍,这会给内存使用情况的准确评估带来困扰。
而分代 ZGC 新的染色指针数据结构通过一些改进规避了这个问题,使得内存使用情况的统计更加准确,有利于系统对内存资源的管理和调度。
分代ZGC 新的染色指针数据结构,支持了更多的color bit(染色位)以支持实现更复杂的算法、扩大了对象地址的存储空间、规避了因使用multi-mapped memory导致的RSS统计为ZGC实际内存使用的3倍。
分代ZGC的 染色指针 colored pointers:
与不分代ZGC的4个颜色位相比,分代ZGC需要12个颜色位来标识不同的GC阶段,这显然不能用多重映射内存来实现了。
为什么 分代ZGC不再使用多重映射技术?
分代ZGC需要更多的标记位,如果还使用 多重映射 muli-map的方式,两个原因:
- 第一分代ZGC用12位染色位,可用内存会因为多加标记位减少;
- 第二RSS指标可能是实际使用内存高出更多倍
分代ZGC No multi-mapped memory(不再使用多重映射内存)

在不分代的ZGC中,通过指针中不同的标记位区分不同的虚拟空间,而这些不同标记位指向的不同的虚拟空间通过mmap映射到同一物理地址。
也就映射3次(M0/M1/remaped),最终造成普通ZGC的RSS指标(RSS统计的虚拟内存地址)翻了3倍。

与不分代ZGC的4个颜色位相比,分代ZGC需要12个颜色位来标识不同的GC阶段,这显然不能用多重映射内存来实现了。

分代ZGC需要更多的标记位,如果还使用muli-map的方式,第一可用内存会因为多加标记位减少;第二RSS指标可能是实际使用内存高出更多倍,所以分代ZGC在把虚拟内存交给操作系统的时候,需要清除标记位。
这也是为啥ZGC一开始不支持分代的原因。
如何在不产生额外成本的情况下去除和恢复颜色?
染色指针只是JVM定义的,操作系统、处理器未必支持。
为了解决这个问题,不分代 ZGC在Linux/x86-64平台上采用了虚拟内存映射技术。
ZGC为每个对象都创建了三个虚拟内存地址,分别对应Remapped、Marked 0和Marked 1,通过指针指向不同的虚拟内存地址来表示不同的染色标记。
不分代 ZGC 仅支持 64 位系统,将 64 位虚拟地址空间划分为多个子空间。
创建对象时,先在堆空间申请虚拟地址,该地址暂时不映射到物理地址。
同时,不分代 ZGC 会在 M0、M1、Remapped 空间中为对象分别申请虚拟地址,这三个虚拟地址映射到同一物理地址。
不分代 ZGC 通过切换这三个视图空间,实现并发垃圾回收。
【不分代 ZGC读屏障】检查指针颜色是否是好的?
普通ZGC 在读屏障中,先加载地址(rbx寄存器中的地址转换为虚拟地址)到rax寄存器,然后通过颜色指针验证地址是否有效(testq),如果不是有效地址,则进入slow_path中 (remap操作完成对象指针修复,通过转发表 转变为有效地址,这就是 指针的自愈)。
由于指针信息直接给到了操作系统,所以普通ZGC需要将三个虚拟地址映射到同一个物理地址上。

- rbx:主要用于存储基地址,是需要保存的寄存器。
- rax:用于算术运算、函数返回值和系统调用,是一个灵活的通用寄存器。
【分代ZGC读屏障】 进行去掉颜色位
分代ZGC先加载地址到rax寄存器中,然后右移address_shift位(右移位数与GC阶段有关),然后判断CF和ZF是否都为0(ja指令的作用),如果该条件成立,则进入slow_path完成对象指针修复(并发标记阶段的指针修复)。
分代ZGC 具体做法:
- 保存在内存中的Java对象引用地址是有颜色的。
- 读取出来处理的时候,通过 Load Barrier 将颜色去掉,之后再去寻址。
- 存储的时候,通过 Store Barrier 将颜色恢复。
Load Barrier 和 Store Barrier 是 ZGC 消耗 CPU 大的一个重要原因
分代ZGC读屏障
load barrier:加载屏障,是从堆中加载对象引用时,由JIT注入的一段代码。
负责 移除染色指针中的元数据位、更新GC重定位对象的过期指针。

分代ZGC先加载地址到rax寄存器中,然后右移address_shift位(右移位数与GC阶段有关),然后判断CF和ZF是否都为0(ja指令的作用),如果该条件成立,则进入slow_path完成对象指针修复(并发标记阶段的指针修复)。

address_shift操作:右移最右移除的低位为1时CF为1,否则CF为0。
右移操作得到的结果为全0,那么ZF为1,否则ZF为0。
由于地址右移时不会得到全0结果,所以这里ZF可以认为是一个0常量。
关键要看CF,而CF的结果由address_shift所决定。

一共4中情况,分别对应于不同的GC阶段的有效地址,有效地址的4个R位中根据当前所处阶段,只有1位为1。
在每种情况中address_shift的值恰好可以把墨绿色的唯一的1移除掉(绿色右侧的移除)。
由于JVM中地址是按8对齐的,对于一个有效的地址来说最小为8,所以低3位一定为0(00001000=8),本着能省就省的宗旨,低3位的0和读标记区进行了重叠。
分代ZGC写屏障
store barrier(存储屏障) 是向堆中存储对象引用时,由JIT注入的一段代码。
负责填充元数据位 以创建染色指针、维护remembered set(老年代中指向年轻代的对象指针)、标记对象正在存活。
由于在读地址的时候把指针信息删除了,所以在写的时候,就要把信息恢复,分代ZGC不得不在写屏障完成这个操作。
在写入的时候,12个染色指针都需要参与。

普通ZGC写入的时候只是保存了地址信息。
分代ZGC在写入时则多做了4个操作。
前两个操作合起来就是检测地址是否需要处理,如果需要处理进入slow_path中处理,这里slow_path主要做了如下操作:
- 并行年轻代SATB 染色;
- 并行老年代SATB 染色;
- 并行Remember Set 染色。
后两条指令这是把地址左移,然后把颜色指针还原。由此可见,在写入上必然会有性能损耗。
SATB(Snapshot-at-beginning)
与非分代ZGC不同,分代ZGC采用了SATB机制,在标记开始阶段,GC对GC根进行快照,在标记结束时,确保标记了快照中所有可达对象。
因此,当对象引用关系中断时,内存屏障将要覆盖的引用值通知GC,然后GC将会标记引用的对象并标记从该对象字段上的引用。
记忆集(remembered sets)
很多GC算法使用卡表来追踪从老年代到新生代的引用,通常卡表是一个大型byte数组,其中一位对应512字节的堆空间,如果老年代堆空间中的对象引用了新生代对象,则对应的卡表位设置为1。
G1则使用remembered set记录region之间的引用,每种不同的GC算法对于remembered set的具体实现均不同,分代ZGC使用位图精确对象位置。
另外分代ZGC有两个记忆集,大约占用了3%的JVM内存消耗。
current remembered set,应用线程负责写入。线程执行过程中,当有新增的从老年代指向新生代的引用,则应用线程将引用信息写入记忆集。
previous remembered set,由GC线程负责扫描和清理。新生代标记开始时,交换current remembered set和previous remembered set。
两个记忆集的好处在于,不需要引入新的内存屏障和内存可行性机制,也避免了GC线程和应用线程的竞争。
Dense heap regions
GC在进行新生代对象转移时,不同page中的存活对象数量和其占用的内存量均不同。
分代ZGC将分析新生代page的内存使用情况和预计回收情况,以确定哪些page值得转移、哪些page转移成本较高。
某些page可能会由于转移成本过高,而原地晋升为老年代。
这种整个page晋升老年代的机制,将减少回收新生代的压力。
